
Understanding Semantic Data Layers


BLUF: Most organizations aren’t losing the data game because they lack data. They’re losing because nobody agrees on what the data means. A semantic data layer is the organizational and technical infrastructure that fixes that. The hard part isn’t building it, but treating data like a product with an owner, a roadmap, and a seat at the leadership table.
If data is the new oil, the oldest legacy enterprises in business should be poised for a whole new wave of investment. But they’re not. And just like oil trapped in the Canadian oil sands, the data is useless until someone figures out how to make it usable.
In most organizations, the pattern is almost predictable. Someone from finance pulls a customer count. Someone from sales pulls a different one. Someone from the data team pulls a third. All three numbers are technically correct. All three are sourced from systems in the same company that someone paid millions to build and maintain. And yet the executive sitting at the head of the table has to choose which one to believe.
That moment of paralysis is not a technology failure, and it isn’t that the people gathering the data don’t know what they’re doing. The problem is systemic. And until organizations treat it as such, no amount of investment in AI, business intelligence, or data modernization will fix it.
Several years ago I was working with a large, established insurance company to develop a strategy for the future. The executive sponsoring the engagement was certain that future profitability would come not from selling insurance and carefully managing a fund, but from their data. I dropped the South Park Underpants Gnome analogy. He didn’t get it.

I tried again: just as stealing underpants isn’t a path to profit, neither is reducing investment in your core products because you’ve decided that data equals revenue. The company was a trusted insurance provider, not a data broker. Their data could make their core business sharper, faster, and more competitive, but only if they could actually use it. That was the part nobody had thought through.
When we dug in, the picture was familiar. They had a lot of data. They also had no coherent way to work with it. It was siloed across systems that didn’t communicate, defined differently by every team that touched it, and governed by nobody in particular. The strategic conversation they thought they were having, about monetization and future revenue, turned out to be a much more foundational one: we shifted to exploring what their data meant, and whether anyone in the organization agreed.
Realize it or not, most organizations today are in the midst of an underpants gnome conundrum of their own.
Over the last several years, across industries and geographies, I’ve seen organizations struggle with what to do with their data and how to make it accessible. The symptom changes. The root cause rarely does.
Somewhere in the organization’s history, someone decided that shared meaning was a problem each team could solve independently. This is a risk I flagged often when organizations pursued aggressive team autonomy models. The larger and more complex an organization’s business, the less likely any team will ever operate with true independence: the system is simply too big. For a while, the methodological purists proved louder than that concern. Organizations pursued the belief that they could succeed as a collection of independent teams, with coordination and planning recast as overhead rather than value. And the consequences of that decision stayed invisible because the cost of misalignment was low enough to absorb. Reports had footnotes. Analysts reconciled manually. Leaders learned which number to cite in which room.
The cost is no longer low enough to absorb. And the reason why is worth understanding before we talk about the solution.
What We Built Before
The concept of a semantic data layer isn’t new. The problem it solves has been with us since organizations started running on more than one system of record. What has changed is how consequential the absence of one has become.
Before semantic layers became a defined category, organizations managed the meaning problem in one of two ways. Both worked well enough for long enough that the problems they created didn’t become visible until the data environment got large enough and interconnected enough to make them unavoidable.
The first approach was ETL-layer logic. Extract, transform, load pipelines became the de facto home for business definitions. If the finance team needed “active customer” to mean something specific, that logic got baked into the pipeline that fed their reporting database. If the sales team needed a slightly different definition for their dashboard, a different pipeline got built with slightly different logic. Over time, organizations accumulated dozens, sometimes hundreds, of pipelines each carrying their own embedded definitions. Nobody documented the differences systematically. Nobody governed them. The pipelines kept running, the definitions kept drifting, and the organization kept producing reports that didn’t agree with each other without anyone being able to explain exactly why.
The second approach was Master Data Management, or MDM. MDM was the enterprise’s formal attempt to solve the meaning problem before semantic layers existed as a concept. It was ambitious: a centralized system of record for the entities that mattered most, customers, products, suppliers, locations, with governance processes to keep definitions clean. In the right conditions, MDM worked. In most enterprise conditions, it didn’t. The implementations were expensive, the governance overhead was heavy, and the business participation required to keep master data current was difficult to sustain. MDM projects became known for taking years and delivering less than promised. Many organizations still carry the scars of a failed MDM implementation, which makes the conversation about semantic layers politically complicated before it even starts.
What both approaches shared was a fundamental design assumption: that the meaning problem was a data problem, solvable by data teams, and that the business’s job was to consume the results rather than participate in defining them. That assumption is where both approaches broke down.
A semantic data layer, properly implemented, rejects that assumption. The technology part is straightforward. The harder part, getting the business to co-own the definitions, is where most organizations struggle and where most of the real work lives.
What the Layer Does
The term sounds like something a data architect invented to win a budget conversation: confuse the accountant with big words.
A semantic data layer is a shared, governed definition of what your data means. Not what it technically contains. What it means. The difference matters more than most technology leaders realize.
Your CRM calls them clients. Your ERP calls them accounts. Your data warehouse references them by a party identifier that means nothing to any human being who hasn’t memorized a data dictionary. When your AI model, your BI dashboard, or your executive report pulls data, it is drawing from at least three different definitions of the same concept. The downstream result is what you saw in that meeting: three numbers, zero trust.
A semantic data layer sits between your source systems and their consumers. It translates technical data structures into business-meaningful definitions, applies consistent business logic, and ensures that when your analytics tool says “active customer,” it means the same thing whether the query hits your CRM, your data warehouse, or your operational database.
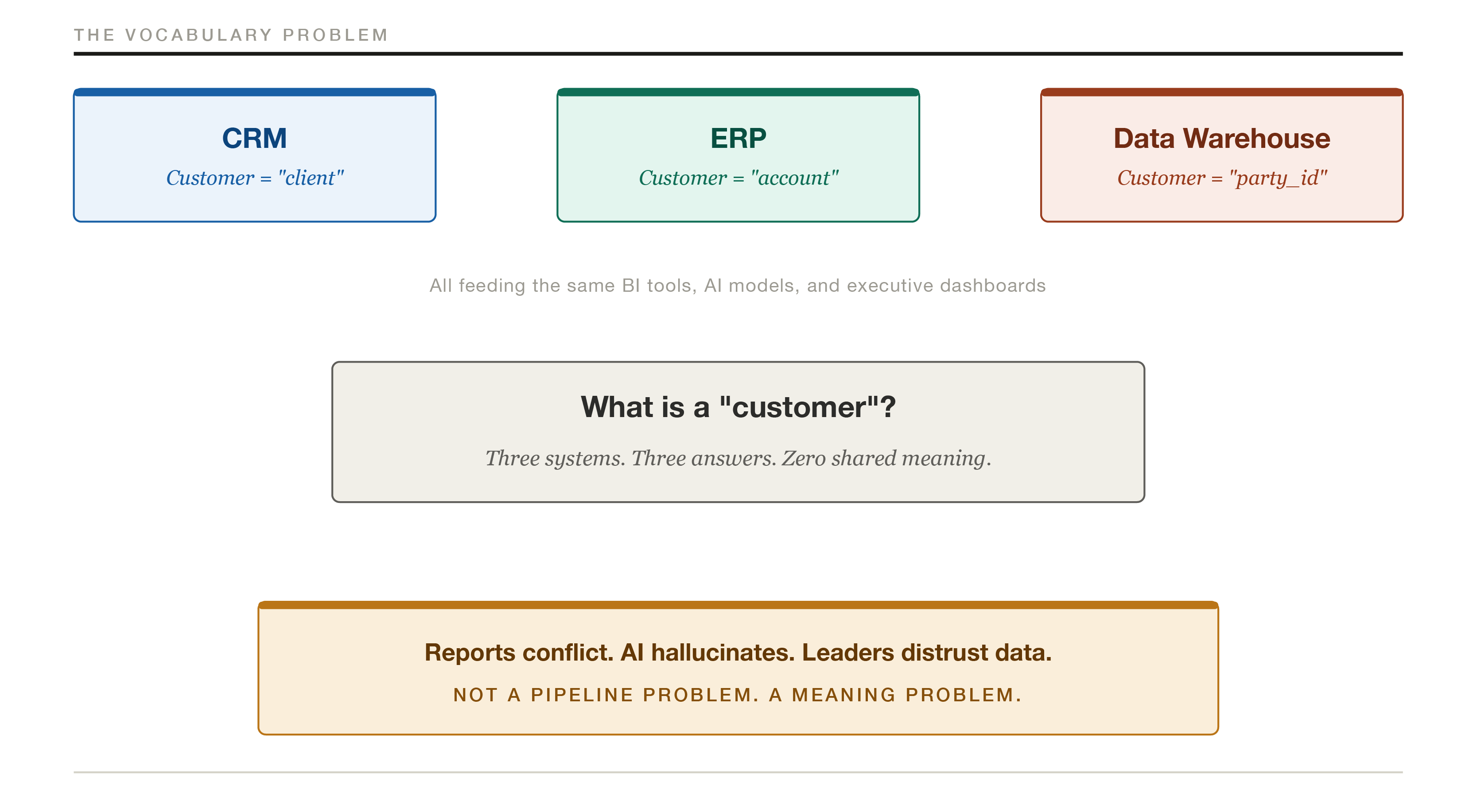
The diagram above illustrates the vocabulary problem. More pipelines won’t fix it. Faster pipelines won’t fix it. A shared dictionary that the systems are required to honor fixes it, and that is what a semantic layer does.
Two Problems, Not One
It is worth being precise about what a semantic layer covers, because two related problems often get conflated in the same conversation.
The first is entity definition: what is a “customer,” a “product,” a “location”? These are the foundational objects your business runs on. When systems use different names or slightly different scopes for the same thing, every report built on top of them inherits the disagreement. This is a structural problem, and it sits underneath everything else.
The second is metric governance: what is “revenue,” “active user,” or “churn rate”? These are calculations, and they can produce different numbers even when the underlying entity definitions agree, because the business logic embedded in the calculation differs by team or tool. Finance calculates monthly recurring revenue one way. Sales calculates it another. Both are pulling from the same source system and still arriving at different answers.
A semantic layer addresses both. But they are not the same problem, and they don’t respond to the same fix. Entity definitions are foundational. Metric governance is built on top of them. The sequence matters: get the entities right first, then govern the metrics built from them. Organizations that skip straight to metric governance without resolving the entity layer underneath tend to find that their governed metrics are consistent but still wrong, because the objects they’re measuring were never properly defined to begin with.
The practical implication is worth stating directly. The “start with ten metrics” advice that appears later in this post is a metric governance move. It is the right place to start building organizational credibility and executive buy-in. But it won’t automatically resolve the entity definition problem underneath. Both need attention, and knowing which one you’re working on at any given moment is the difference between a semantic investment that compounds and one that plateaus.
The Urgency
For years, the absence of a semantic layer was a nuisance organizations could manage. Reports required footnotes. Analysts reconciled manually. Leaders learned which number to cite in which room. The tax was real, but it was distributed and largely invisible.
Generative AI has transformed that manageable nuisance into a structural liability, and it is doing so faster than most organizations realize.
The investment thesis behind most enterprise AI initiatives assumes that connecting capable models to rich data produces reliable insight. That assumption depends entirely on the data being consistent and trustworthy. When it isn’t, when “customer” means three different things in three different systems and none of those systems is authoritative, the model does not throw an error. It synthesizes. It finds a plausible answer from the available inputs and delivers it in whatever format you asked for, with no indication that the foundation it reasoned from was broken.
This is not a model problem. The models are performing as designed. The problem is that the data infrastructure most large organizations have built over the last two decades was not designed with shared meaning as a requirement, because the cost of inconsistency was low enough to absorb before AI made that cost visible.
The risk compounds further as organizations move toward agentic AI. A confused reasoning system that produces a wrong answer is a problem you can catch in review. A confused agent that takes a wrong action, updating a customer record, routing a transaction, triggering a downstream workflow, based on a semantically broken input is a different category of problem entirely. The stakes of semantic inconsistency go up significantly when AI moves from answering questions to taking actions.
The flip side is worth stating plainly. Organizations that do establish semantic clarity before connecting AI to their data get something their competitors don’t: a model that reasons from a shared, trustworthy foundation. That means more reliable answers, faster time to insight, and AI outputs that executives are willing to act on rather than second-guess. Semantic clarity doesn’t just reduce AI risk. It is what makes AI genuinely useful at the enterprise level.
I’ve seen this shift accelerate in a specific way. Engagements that a few years ago started with “we need better reporting” now start with “we’re deploying AI and our outputs aren’t reliable.” When the conversation reaches that point, semantic inconsistency is almost always part of the diagnosis. The organizations moving fastest to fix it aren’t doing so because they read about semantic layers. They’re doing so because a failed AI initiative made the cost of inconsistency impossible to ignore.
Organizations that invest in AI capability before establishing semantic clarity are not getting ahead of the problem. They are getting behind it faster.
The Gap Is Costing You
The cost of semantic inconsistency tends to be invisible on any individual line of the budget. Analysts spend time reconciling instead of analyzing, governance programs stall without shared definitions to govern against, and the cost compounds quietly across every team that touches data.
The most visible damage shows up at the top. The three-numbers problem doesn’t just create a moment of awkwardness in an executive meeting, it creates a pattern of hesitation that slows everything down. Leaders who have learned not to trust their data ask more questions before committing. They wait for reconciliation. They hedge. That caution is rational given the environment they’re operating in, and it is expensive.
The Failure Modes
The absence of a semantic layer creates predictable, consistent problems across organizations regardless of industry, size, or technical maturity.
Definitions get negotiated in spreadsheets. In the absence of a governed layer, individual teams create their own definitions and encode them in Excel files, BI reports, and tribal knowledge. Those definitions drift over time, diverge across teams, and become almost impossible to reconcile systematically because they were never managed as organizational assets. They were managed as individual workarounds.
New systems inherit old ambiguity. When organizations implement a new ERP, a new CRM, or a new data platform, they almost always bring the definitional inconsistency forward with them. The migration project focuses on moving data. Nobody has a mandate to resolve what the data means. The new system goes live with the same meaning problem the old system had, plus new terminology to argue about.
The data team becomes the scapegoat. When reports disagree, someone has to take the blame, and it almost always lands on the data engineering team, because they built the pipelines the reports run on. In most cases, the data team is not actually at fault. They implemented what was asked of them, often by multiple business stakeholders with conflicting requirements. The fault is organizational: no one with sufficient authority held the business accountable for providing consistent definitions before the technical work was done. The data team absorbs the blame for a governance failure that sat above them.
BI tools multiply the problem rather than solving it. Organizations that invest in self-service analytics hoping to broaden data access sometimes find that they have instead broadened data inconsistency. When every analyst can build their own reports, and every report can embed its own business logic, the number of competing definitions of any given metric grows with the number of analysts. The semantic layer problem doesn’t get easier as BI tooling gets more accessible. It gets harder.
AI answers the wrong question fluently. A language model connected to semantically inconsistent data doesn’t know it is working from inconsistent inputs. It synthesizes what it finds and presents it with the confidence of a well-trained communicator. The result is answers that sound authoritative and are frequently wrong in ways that are difficult to detect without already knowing the answer. This is the failure mode that is moving the semantic layer conversation from data team priority to C-suite priority faster than most other forces in enterprise technology right now.
The Infrastructure Trap
Most organizations that do invest in a semantic layer make a consistent mistake: they treat it as infrastructure rather than as a product. The distinction is not a small one. It has concrete operational consequences.
Infrastructure gets built once. It gets documented once. It gets maintained reactively, when something breaks. Nobody owns it in a meaningful way. Nobody measures whether it’s working. The business never really asked for it, which means the business has no stake in keeping it current.
A semantic layer treated as infrastructure decays. Business definitions change. New source systems get added. Organizational mergers bring in entirely new vocabularies. Nobody updates the layer because nobody’s job it is to update it. Within eighteen months, the layer that was supposed to create shared meaning has become another source of inconsistency, only now with the additional problem of looking authoritative while being wrong.
The difference between the two approaches is illustrated below.

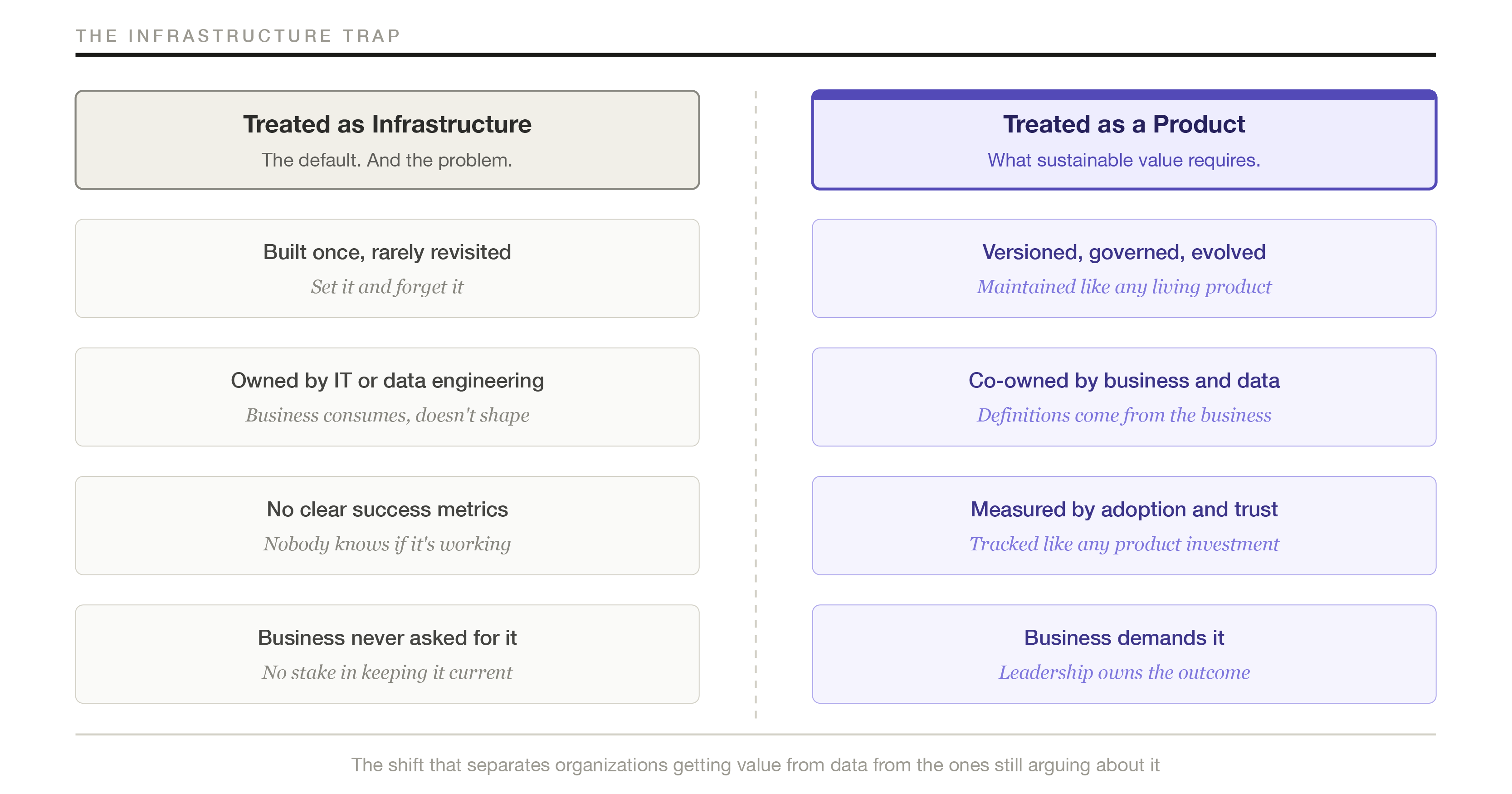
The organizations getting real value from their semantic investments treat the layer as a product. That means it has owners. It has a roadmap. It has adoption metrics. Business stakeholders are part of the governance process, not passive recipients of definitions handed down from IT. The definitions evolve as the business evolves, through a deliberate change process rather than through drift.
Treating semantic data as a product is a governance decision as much as a technology decision. It requires someone with organizational authority to hold both the technical and business sides of the conversation accountable to the same vocabulary.
Getting It Right
The enterprises I have seen navigate this successfully share a consistent set of moves. None of them are complicated in concept. All of them are hard in practice.
Put a senior executive in charge of data strategy, not just data operations. This is the move that separates organizations that resolve the semantic problem from the ones that keep managing around it. The definitional disagreements that prevent a semantic layer from taking hold, what counts as a closed deal, what makes a customer active, how revenue is calculated across business units, are not questions a data engineering team can answer. They require someone with organizational authority to convene the right business stakeholders, surface the disagreements, and make binding decisions.
In practice, this means a Chief Data Officer, or a senior executive with equivalent authority, who holds both the business and technology sides of the semantic conversation accountable. Not a data steward committee with no enforcement mechanism. Not a center of excellence that produces recommendations business units are free to ignore. An executive with a mandate to establish and maintain shared definitions, the organizational leverage to hold business units accountable to those definitions, and a reporting line that makes data strategy a C-suite concern rather than a back-office function.
The organizations that have gotten this right have typically made this move before the AI conversation started, which is one of the reasons their AI initiatives are performing better than their peers. The semantic foundation was established because someone with authority decided that shared meaning was a strategic requirement, not an IT project. The AI capability was layered on top of a foundation that could support it.
Start with the entities your systems disagree about most, then move to the metrics your leadership team argues about most. Get the foundational objects right first: customer, product, location, account. Then define, formally, in writing, with sign-off, the business concepts that generate the most disagreement when they appear in executive reports. Revenue. Active user. Churn. Margin by product line. Both layers of work matter. Neither substitutes for the other. Getting them sequenced correctly is what makes the investment compound rather than stall.
Treat the semantic layer’s health as a board-level metric. The organizations that sustain this over time measure it the way they measure any product: adoption rates across business units, query volume against governed definitions versus ad hoc queries, time-to-answer for common business questions, and whether executives actually believe the numbers they’re seeing. These aren’t vanity metrics. They are leading indicators of whether the investment is growing stronger or quietly falling apart.
The Takeaway
The technology leaders positioned well on the other side of this problem aren’t the ones who bought the best semantic layer tooling. They’re the ones who recognized early that the meaning problem is an organizational problem, and made the leadership investments required to solve it at that level.
That work is not glamorous. It involves sitting in rooms where executives from different business units disagree about the definition of their most important metrics, and holding the line that the organization needs a single answer rather than a convenient plurality of them. It involves explaining to a board why a data governance initiative is a strategic investment rather than a cost center. It involves building the organizational infrastructure that makes AI initiatives reliable, which is less visible than the AI initiatives themselves but more important to whether they actually succeed.
The leaders who look back on this period with satisfaction won’t be the ones who deployed the most AI pilots or adopted the most capable models. They’ll be the ones who asked the harder question first: does our organization have a shared language for what our data means? And then built the organizational infrastructure required to answer it.
That infrastructure starts with someone in the room who has the authority and the will to say: we are not leaving until we agree on what a customer is.