
From SDLC to ADLC.
Your SDLC Doesn't Know What to Do With AI. It's Costing You $ & %.


BLUF: The Software Development Lifecycle was built for a world where software shipped on a schedule. Unfortunately, our AI-augmented world doesn’t work on a schedule. CIOs who keep mapping AI initiatives onto SDLC assumptions are doing worse than just slowing things down. They’re structurally misaligned with how value actually gets created now, and the gap between organizations that figure this out and the ones that don’t is widening faster than most people realize.
The pattern is undeniable. The AI pilot lands well. Leadership gets excited. Someone stands up a project team, drops it into the delivery framework, and the whole thing slows to a crawl. Eighteen months later, the board asks what happened, and the honest answer nobody gives is: we tried to deliver a different kind of work using a process designed for a different era.
I’ve seen this play out time-and-time again; delivery frameworks failing, people scrambling, only to be left asking “why?”. The teams aren’t failing. The technology isn’t failing. The system is failing. (Where have I seen this movie before?) In this case, the system is the SDLC.
Let’s be clear, this isn’t a process optimization problem that we can “Lean” our way out of. You can’t iterate your way out of it, either. What’s breaking is more fundamental than that, and the organizations getting ahead of it aren’t doing it by running better retrospectives.
What the SDLC Was Built For
To understand why it’s breaking, it helps to understand what it was designed to solve.
Enterprise software development in the mainframe and early client-server era was expensive, slow, and largely irreversible. Hardware constraints meant that rework was operationally dangerous. Requirements had to be locked early. Testing had to be exhaustive. Release cycles were long because deployment itself was a high-stakes event with real failure modes.
In my early days of operations consulting, I remember working with an enterprise client who was certain there was no way they could release more frequently than once per three years due to the dangers of the “corporate load.” We managed to reduce that cycle to a quarterly release, but doing so safely required re-architecting the entire tech-stack and a good bit of their business operations as well. Too many consultants are quick to peg this a “leadership problem” without thoroughly understanding the complexity of the operations. The point is, the SDLC as we know it served a purpose. And, even in 2026, in some enterprises, that context still exists.
The SDLC emerged as a rational response to those constraints. Define the work, sequence it, gate it, ship it. That model worked remarkably well for decades, and it produced a generation of enterprise delivery professionals who built discipline around it.
Agile modernized the cadence. Two-week iterations instead of multi-year waterfall projects. Incremental delivery instead of big-bang release. Continuous feedback instead of requirements locked in Phase 1. It was a genuine improvement, and it’s the right model for a wide class of software work.
But here’s what Agile didn’t change: the underlying assumption that the job is to build a defined thing to a defined specification, and ship it.
That assumption is what AI breaks.
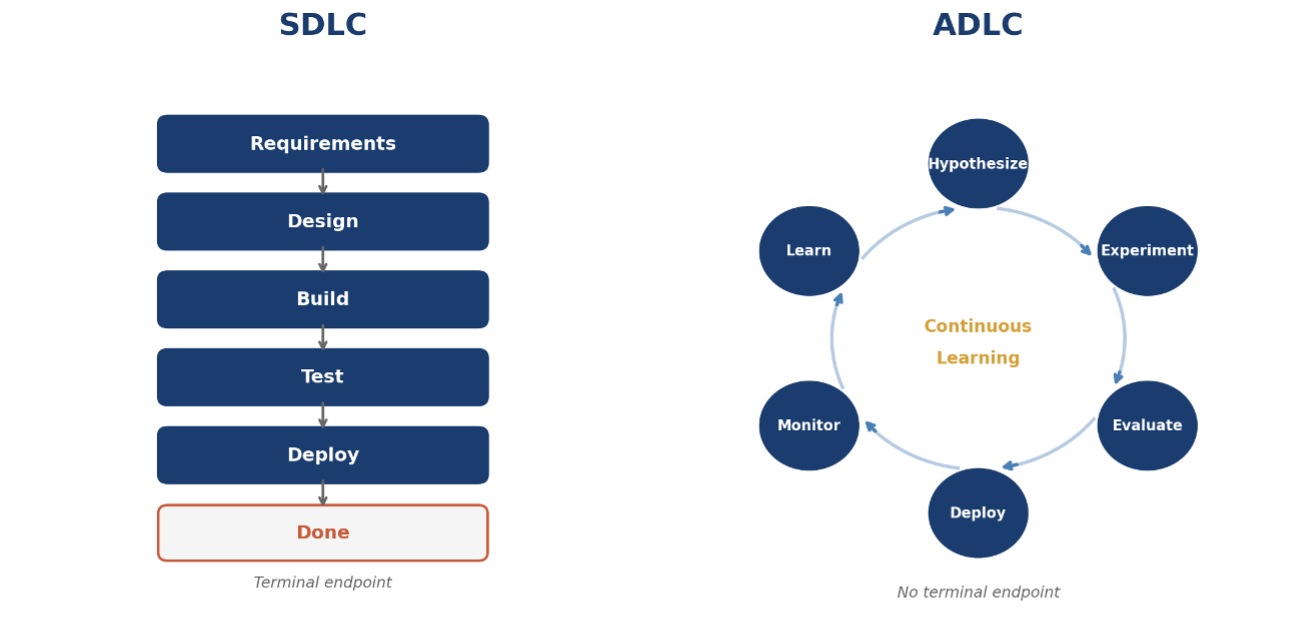
AI Development Doesn’t Have a Finish Line
Traditional software is deterministic. Given the same inputs, a well-built system produces the same outputs. You can write a requirement for it, test against it, and know when you’re done. The definition of done is binary: it works as specified, or it doesn’t.
AI systems are probabilistic. Given the same inputs, a model produces outputs that vary based on training data, fine-tuning decisions, inference parameters, and the statistical properties of the task. There is no requirement you can write that fully specifies model behavior in advance, because the model’s behavior is an emergent property of training on data, not a direct implementation of logic.
This has concrete consequences for how an enterprise manages delivery. You don’t write requirements for a model. You define a problem, form a hypothesis, run experiments, evaluate outputs against business outcomes, deploy, observe real-world behavior, and iterate based on what you learn. The specification for success is probabilistic and contextual, not binary and universal.
A model that performs well in evaluation can perform differently in production because production data has different statistical properties. A model that performs well in one customer segment can underperform in another. A model that performs well in March can drift by September because the world it’s predicting has changed.
There is no “shipped” state that ends the development work. The model in production is a living artifact. It requires ongoing monitoring, evaluation, retraining, and refinement as long as it’s in use.
The model in production is still a development artifact. There is no “done.”
Sources: Andrew Ng, “AI Transformation Playbook,” Landing AI; Sculley et al., “Hidden Technical Debt in Machine Learning Systems,” NeurIPS 2015; Google, “Practitioners Guide to MLOps,” 2021
When You Force AI Into an SDLC Container
When AI development gets managed through SDLC assumptions, the consequences are predictable and consistent. I’ve seen the same patterns across clients regardless of industry, size, or technical maturity.
Requirements get written for unknowable things. Business stakeholders are asked to specify model behavior before anyone has run a single experiment. The result is requirements that are either so vague as to be useless or so specific as to be wrong. Neither gives the team what it needs to deliver actual business value.
Iteration velocity becomes a fiction. AI development work doesn’t decompose cleanly into stories and tasks. The value isn’t in completing a ticket, it’s in learning whether a hypothesis is true. A sprint where the team ran three experiments and learned that two approaches don’t work is a successful sprint. In an Agile framework, it looks like zero velocity. So teams game the metrics.
Definition of done gets misapplied. A model is never done; it’s just performing at a certain level given current data and conditions. Organizations that apply traditional done criteria to AI work end up either declaring victory on systems that aren’t actually working, or never declaring anything done because the goalpost keeps moving.
Production becomes an afterthought. SDLC treats production as the end state. In AI, the production signal is a development input. What happens when real users interact with the model is data you need to improve it. Organizations that separate development from operations for AI work are cutting off their most valuable feedback source.
Governance creates adversarial dynamics. Phase-gate reviews were designed to catch scope creep in projects with known deliverables. They are not equipped to evaluate AI initiatives where the right path forward isn’t knowable in advance. So they slow things down without adding value. Teams learn to perform for the review rather than doing the work that matters.
Sources: Amershi et al., “Software Engineering for Machine Learning: A Case Study,” Microsoft Research, 2019; Sculley et al., NeurIPS 2015
The ADLC Is a Different Set of Physics
The AI Development Lifecycle isn’t a replacement for discipline, but a discipline built for different physics. And the differences aren’t cosmetic.
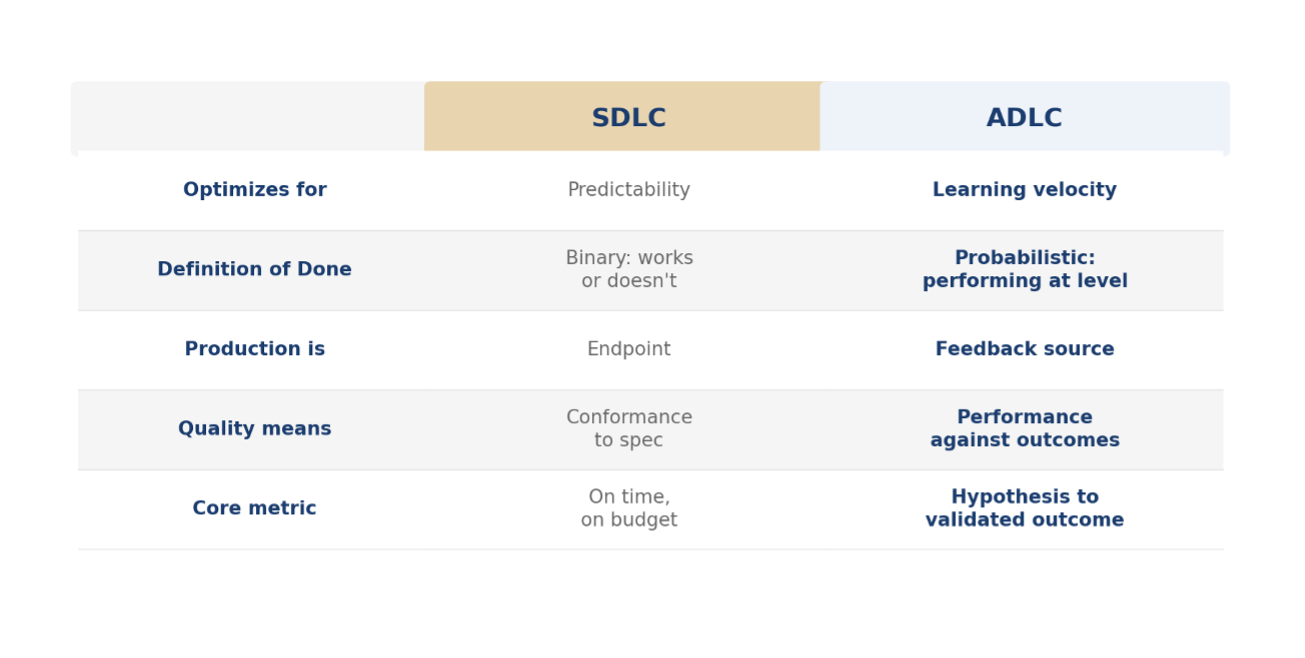
Where SDLC optimizes for predictability, ADLC optimizes for learning velocity. The measure of a healthy ADLC isn’t how closely the team hit their iteration commitments. It’s how quickly they moved from hypothesis to validated outcome, and how much of what they learned in production shaped the next iteration.
Where SDLC treats production as the endpoint, ADLC treats production as a continuous feedback source. Monitoring, observability, and model performance tracking aren’t post-delivery operations concerns. They are core development infrastructure that has to be designed and built before the first model ships.
Where SDLC separates development from operations, ADLC requires them to be integrated. MLOps, the operational discipline that makes this integration work, has matured considerably. But most enterprise organizations haven’t restructured their teams to take advantage of it, because doing so requires dismantling organizational boundaries that have been in place for decades.
Where SDLC measures quality as conformance to specification, ADLC measures quality as performance against outcomes.
A well-functioning ADLC asks:
What business outcome is this model driving?
How is that outcome trending over time?
Where is the model underperforming relative to opportunity?
A well-functioning SDLC asks:
Are we on schedule?
Are we on budget?
Did we hit the acceptance criteria?
Those are the right questions for the wrong problem.
The organizations getting real value from AI are not the ones with the best SDLC hygiene. They’re the ones that stopped asking their SDLC to do work it wasn’t designed to do.
Sources: Kreuzberger et al., “MLOps: Overview, Definition, and Architecture,” 2022; Google, “Practitioners Guide to MLOps,” 2021
Why the Mismatch Keeps Winning
If the problem is this clear, why is it so consistent? Because the incentive structures that govern enterprise technology delivery are built on SDLC assumptions, and those structures don’t change just because the work does.
Funding models expect a scope, a timeline, and a deliverable. Capital expenditure frameworks are designed around projects with terminal endpoints. AI capabilities don’t have terminal endpoints. Organizations that fund AI initiatives the same way they fund a new ERP implementation end up either underfunding continuous development work or forcing it into artificial project structures that don’t reflect how the work actually operates.
Governance frameworks expect phase gates. ADLC’s continuous iteration model looks, to a traditional governance body, like a team that never finishes anything. The natural institutional response is to add more structure: more gates, more documentation requirements, more review cycles. The structure makes the problem worse.
Organizational metrics reward on-time, on-budget delivery of defined scope. They don’t have vocabulary for “we ran twelve experiments, eight didn’t work, four produced insights that changed our approach, and we’re now three months ahead of where we’d be.” That outcome looks like replanning. It gets scored as underperformance.
Talent structures were built around role definitions that separate development from operations. The people who build software and the people who run it are different teams, different career tracks, different management chains. AI work requires them to be the same conversation. Reorganizing around that requirement is hard, and most organizations haven’t done it.
The people running these frameworks aren’t the problem. They built strong discipline for real problems. The issue is the assumption that the same framework governs work that operates by completely different rules. That assumption is invisible until it costs you something.
For CIOs, the practical consequence is a team executing well on the wrong model and getting punished for it. That is a leadership problem, not a delivery problem. It won’t be solved by better retrospectives.
What the Organizations Getting It Right Do
The enterprises I’ve seen navigate this transition successfully share a consistent set of moves. None of them are complicated in concept. All of them are hard in practice because they require changing structures that have organizational momentum behind them.
• Reform the funding model first. AI capabilities need to be funded as ongoing operational investments, not capital projects. The SAFe Lean Portfolio Management model offers a practical solution: replace traditional project-based funding with Lean Budgets allocated to value streams, governed by guardrails rather than detailed upfront business cases. Funding flows to the capability continuously, and reallocation decisions happen at cadence-based portfolio sync events rather than through formal change control. For organizations with existing SAFe adoption, this isn’t a new concept, it’s applying LPM discipline to AI investment the same way you’d apply it to any product value stream. For organizations without it, the principle still translates: fund the team and the capability, not the project. Treat improvement over time as a success criterion, not an exception. Frame it as a shift from “build and done” to “build and run” — a model finance already understands from infrastructure investment, and one that SPM practitioners recognize as the natural extension of participatory budgeting into AI operational spend.
• Redesign governance, don’t bypass it. The question shifts from “is this project on track against original scope?” to “is this capability performing against business outcomes, and are we learning fast enough to keep improving it?” Portfolio Kanban gives you the structural answer here: AI initiatives flow through portfolio-level visibility as epics, with progression gates tied to hypothesis validation rather than phase completion. Instead of asking “did we finish the build phase,” you’re asking “did we validate the business hypothesis that justified this investment?” That’s a meaningful governance event. Pair that with Weighted Shortest Job First prioritization at the LPM level and you have a framework for making active reallocation decisions based on learning, not waiting for a quarterly steering committee to approve a change request. For organizations with mature SPM functions, this maps directly to the strategic portfolio review cadence: AI capabilities belong on the portfolio Kanban board alongside other value stream investments, governed by the same outcome-based guardrails, not siloed into a separate “AI governance” structure that operates outside normal portfolio discipline.
Change what you measure. The delivery metrics that matter for SDLC tell you nothing useful about AI initiative health. The metrics that matter for ADLC: how quickly are we moving from hypothesis to validated outcome? Is model performance improving or degrading over time? What’s our data drift detection latency? How much of what we observe in production is feeding into the next development cycle?
Integrate development and operations structurally. Some organizations start by creating AI capability teams that own both development and operations for specific use cases, then use those teams as a model for broader structural change. The common thread is making the production signal a first-class development input, whatever structural form that takes.
Sequence the transition intentionally. The organizations that try to shift everything at once tend to create chaos without benefit. The ones that do it well start with one or two AI capabilities of sufficient strategic importance to justify building the right infrastructure around them, then use those as proof points to drive broader organizational change.
A Note on What This Is Not
This is not an argument against rigor. SDLC disciplines emerged because software development without structure produces expensive, late, and incorrect software. The discipline is real. The need for discipline in AI development is equally real.
What ADLC rejects isn’t rigor. It rejects the specific application of SDLC-shaped rigor to AI-shaped work. The rigor looks different: hypothesis-driven experimentation instead of upfront requirements, outcome metrics instead of acceptance criteria, continuous monitoring instead of pre-release testing, production observation instead of deployment as endpoint.
This is also not an argument that SDLC is dead. A significant portion of enterprise technology work is still traditional software development, and it should still be managed with SDLC discipline. The point is that organizations need to distinguish between which work fits which model, and stop applying SDLC assumptions uniformly across a portfolio that increasingly contains AI capabilities requiring a different approach.
The CIOs I see struggle are the ones who either try to run AI work like software development, or overcorrect by treating all AI work as uniquely ungovernable. The right answer is structural clarity: different work requires different delivery models, and the organization needs the capability to run both.
What This Is Asking of You
The technology leaders positioned well on the other side of this transition aren’t the ones who ran the fastest pilots. They’re the ones who recognized early that delivering AI value requires different organizational infrastructure, and made the structural investments to build it.
That work is not glamorous. Funding model conversations with CFOs who have capital budgeting frameworks that are forty years old. Governance redesign with boards who want phase gates and milestone reviews. Metric evolution with business stakeholders who want to know what they’re getting and when. Team restructuring with engineering leaders who have built their careers around role definitions that need to change. None of it generates the announcement that a new AI product went live. All of it determines whether the AI capabilities you’re building actually improve over time, or plateau and decay.
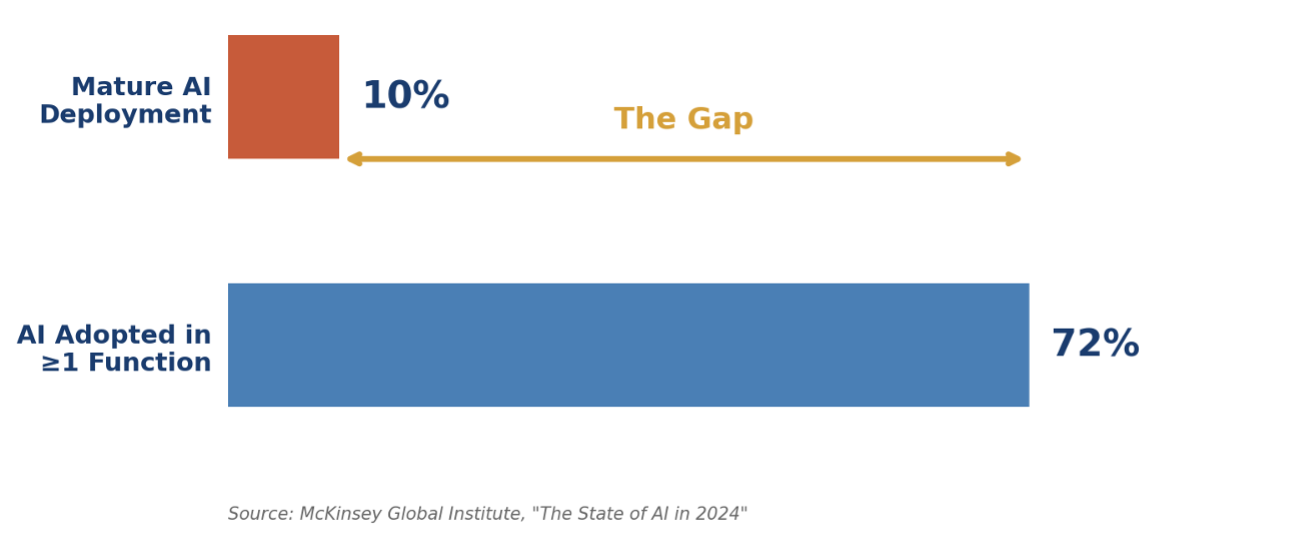
The data on where most organizations are right now isn’t encouraging. McKinsey’s 2024 State of AI report found that while 72% of organizations had adopted AI in at least one business function, fewer than 10% described themselves as having mature AI deployment capabilities — defined as the ability to move from pilot to production to continuous improvement systematically. The gap between “we ran some pilots” and “we have an organizational capability to develop and operate AI” is where most enterprises currently live.
That gap isn’t a technology problem. It’s an organizational architecture problem. And it won’t close by running better sprints.
The CIOs who look back on this period with satisfaction won’t be the ones who ran the most pilots. They’ll be the ones who built the organizational infrastructure AI actually requires.
Sources: McKinsey Global Institute, “The State of AI in 2024,” May 2024; Gartner, “AI Engineering: A Key Capability for Scaling AI,” 2023
The Takeaway.
The SDLC was a genuine achievement. The discipline it created, applied at scale, produced decades of reliable enterprise software delivery. That’s not nothing.
The work has changed. The work of developing AI capabilities operates by different rules, and the organizational infrastructure required to do it well is different from the infrastructure enterprises have spent decades building. The gap between those two realities is where most AI investment gets lost right now.
The leaders who navigate this well won’t be the ones who shipped the most pilots. They’ll be the ones who recognized that the organizational architecture question is the real one, made the structural investments to answer it, and built the continuous capability to develop, operate, and improve AI in a way that compounds over time.
That’s harder work than optimizing a sprint ceremony. It requires holding the tension between near-term pressure that is absolutely real and structural change that takes longer than a quarter but matters more than any individual initiative. And it requires someone in the room willing to name the actual problem instead of proposing a better version of the solution that isn’t working.
If you’re a CIO working through what that transition looks like in your organization, I’m interested in that conversation. The variables are real, the path is navigable, and the distance between organizations that figure it out and the ones that don’t is compounding faster than most people want to admit.
Care to chat? Find me on LinkedIn.
https://rkpaleru.substack.com/p/beyond-the-hype-building-enterprise?utm_campaign=post&utm_medium=web
Posted very similar thoughts, but on how we believe this can be achieved.